In the world of data handling and transfer, one common challenge that arises is backpressure. If you’ve ever encountered a situation where data starts to accumulate like a clog while being transferred, you might have experienced backpressure. In this blog post, we’ll explore what backpressure is, how it affects data handling in Node.js, and how streams offer an optimized solution to deal with this issue effectively.
What is Backpressure?
Backpressure occurs when there is a data transfer mismatch between the sender and receiver. The receiving end, due to its complexity or slow processing, cannot keep up with the data flow from the sender. As a result, data starts to pile up, causing inefficiency and potential memory exhaustion.

Fig 1: data pile up due to no backpressure

Fig 2: efficient handling with backpressure
The Role of Streams in Nodejs
Before diving deeper into backpressure, let’s understand the role of streams in Nodejs. Streams are instances of EventEmitter and come in different types, including Readable, Writable, Duplex, and Transform. They allow data to be read or written in chunks, which is particularly useful for large datasets. Read in more detail Streams: An underrated but very powerful concept in NodeJS
Backpressure Mechanism and Flow Control
In Nodejs, data is often transferred from one process to another using streams. However, when data is transferred from one stream to another, backpressure can become a real concern.
To tackle the backpressure issue, a backpressure mechanism is implemented in Nodejs streams. When data is being written to a stream, the .write() method returns a boolean value indicating if it is safe to continue writing data. If the return value is false, it means the write queue is busy, and the stream is experiencing backpressure. In such cases, the stream pauses data consumption until the write queue is free, allowing for a smooth and optimized data flow.
Optimization with Streams
Nodejs offers various ways to optimize data transfer using streams. One common practice is using the .pipe() method, which allows data to flow seamlessly from a Readable stream to a Writable stream. The backpressure mechanism works hand in hand with .pipe() to ensure that data is processed efficiently without overloading the receiving end.
Lifecycle of .pipe()
To achieve a better understanding of backpressure, here is a flow-chart on the lifecycle of a Readable stream being piped into a Writable stream:
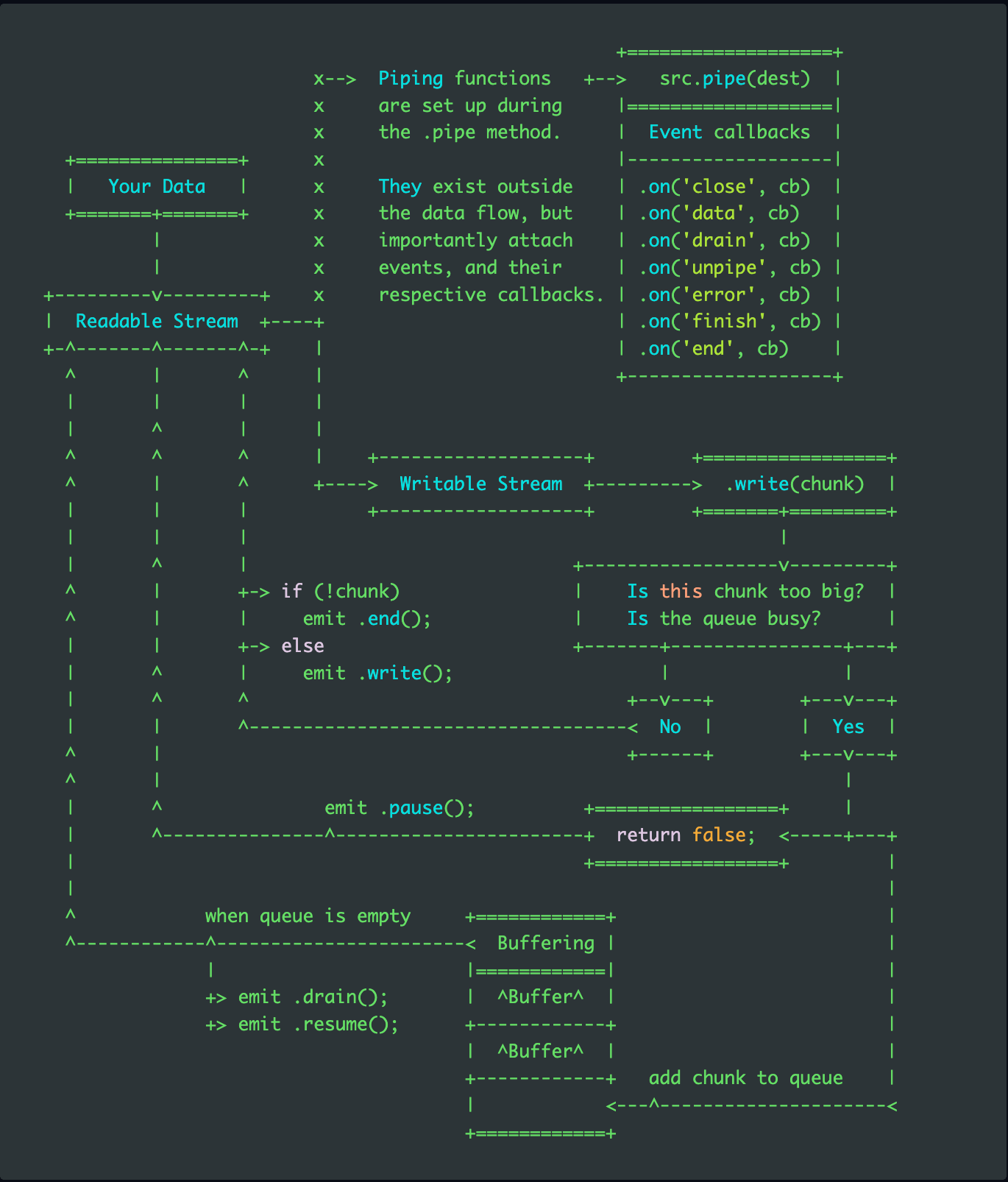
Source: Lifecycle of .pipe()
If you are setting up a pipeline to chain together a few streams to manipulate your data, you will most likely be implementing Transform stream.
In this case, your output from your Readable stream will enter in the Transform and will pipe into the Writable.
Readable.pipe(Transformable).pipe(Writable);
Backpressure will be automatically applied, but note that both the incoming and outgoing highWaterMark of the Transform stream may be manipulated and will effect the backpressure system.
For detailed write up please read the official documentation Backpressuring in Streams.
Conclusion
Backpressure is an important consideration in data handling, especially in environments like Nodejs, where large amounts of data are transferred. Understanding the backpressure mechanism and leveraging streams can greatly improve the efficiency and reliability of data processing. As the world of data continues to grow, mastering backpressure and stream optimization is a valuable skill for any Nodejs developer.
✨ Thank you for reading and I hope you find it helpful. I sincerely request for your feedback in the comment’s section.
